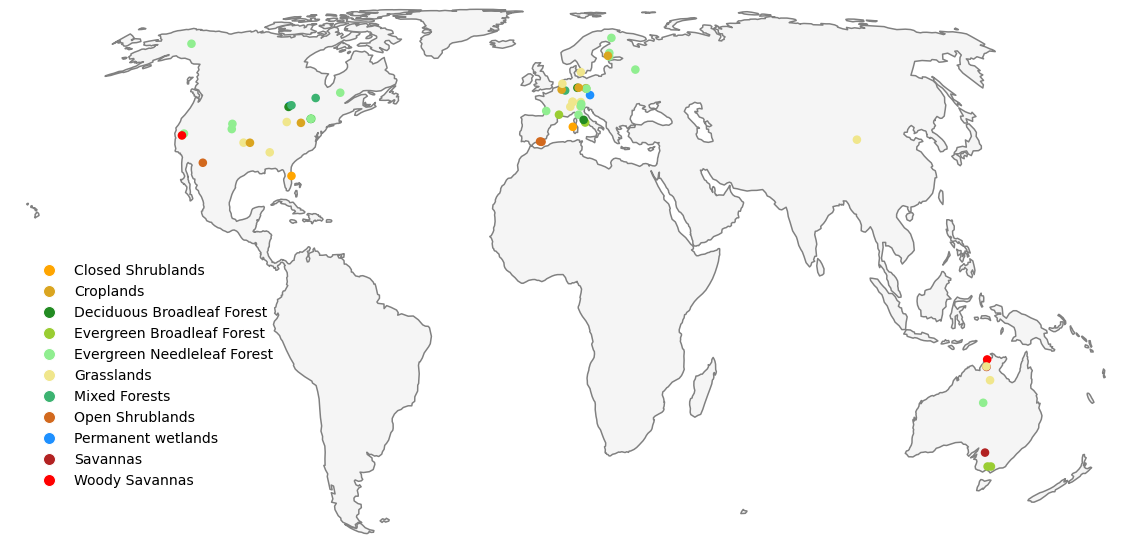
While machine learning (ML) techniques have proven to have exceptional performance in prediction of variables that have long and varied observational records, it is not clear how to use such techniques to learn about intermediate processes which may not be readily observable. We build on previous work that found that encoding either known, or approximated, physical relationships into the machine learning framework can allow the learned model to implicitly represent processes that are not directly observed, but can be related to an observable quantity. Zhao et al. (2019) found that encoding a Penman-Monteith-like equation of latent heat in an artificial neural network could reliably predict the latent heat while providing an estimate of the resistance term, which is not readily observable at the landscape scale. Specifically, we advance this framework in two ways. First, we expand the physics-based layer to include the partitioning of both the latent and sensible heat fluxes among the vegetation and soil domains, each with their own resistance terms. Second, we couple a land-surface model (LSM), which provides information from simulated processes to the ML model. We thus effectively provide the ML model with both physics-informed inputs as well as maintain constraints such as mass and energy balance on outputs of the coupled ML-LSM simulations. Previously we found that coupling a LSM to the ML model could provide good predictions of bulk turbulent heat fluxes, and in this work we explore how incorporating the additional physics-based partitioning allows the model to learn more ecohydrologically-relevant dynamics in diverse biomes. Further, we explore what the model learned in predicting the unobserved resistance terms and what we can learn from the model itself. Zhao, W. L., Gentine, P., Reichstein, M., Zhang, Y., Zhou, S., Wen, Y., et al. (2019). Physics-Constrained Machine Learning of Evapotranspiration. Geophysical Research Letters, 46(24), 14496–14507. https://doi.org/10.1029/2019GL085291