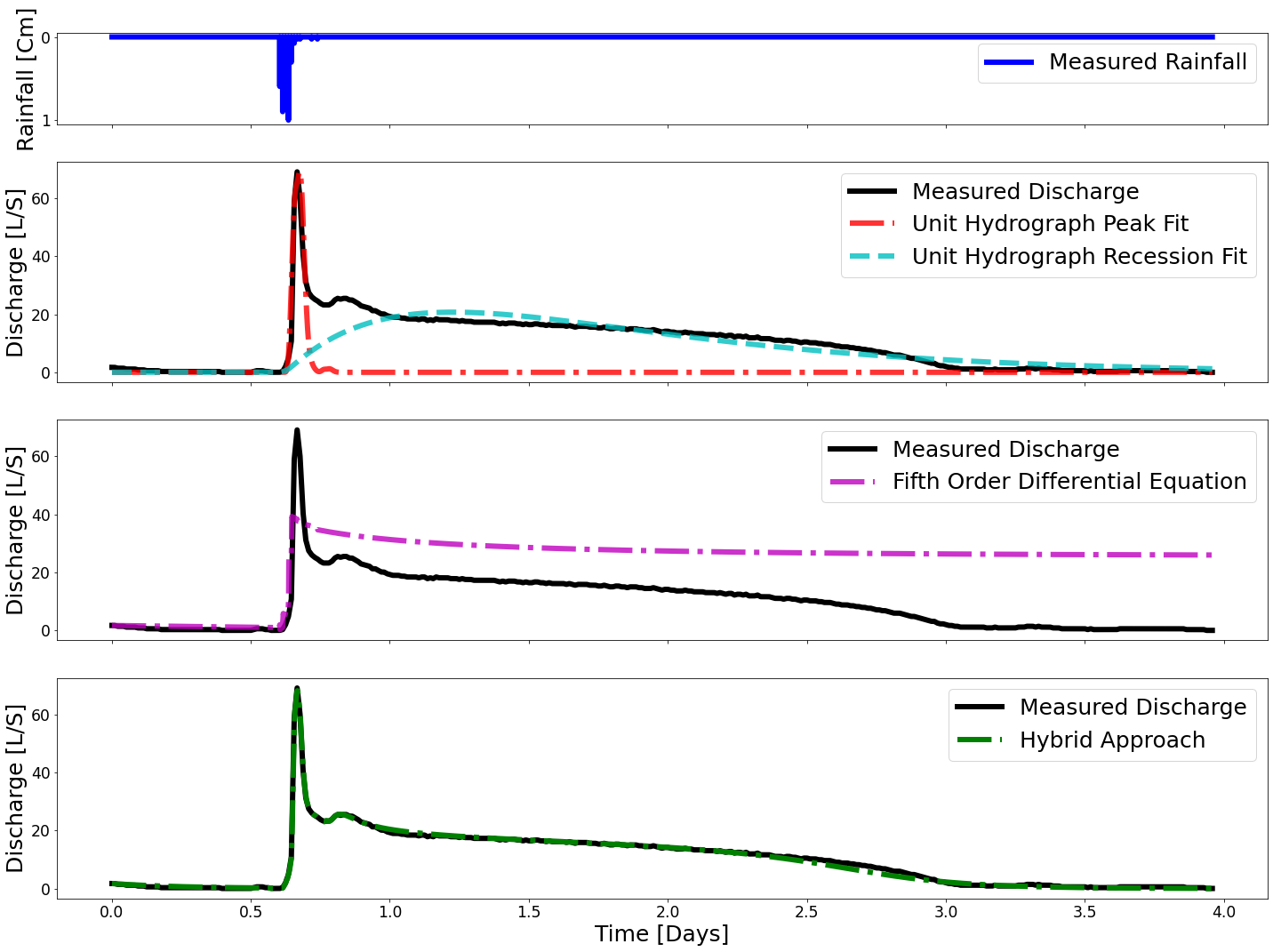
A sudden surge of data has created new challenges in water management, spanning quality control, assimilation, and analysis. Few approaches are available to integrate growing volumes of data into interpretable results. Process-based hydrologic models have not been designed to consume large amounts of data. Alternatively, new machine learning tools can automate data analysis and forecasting, but their lack of interpretability limits the discovery of insights and may impact trust. To that end, we present a new approach, which seeks to strike a middle ground between process-, and data-based modeling. The contribution of this work is an automated and scalable methodology, which discovers differential equations and latent state estimations within hydrologic systems using only rainfall and runoff measurements. We show how this enables automated tools to learn interpretable models solely from measurements. We apply this approach to fourteen stream gaging sites across the US, showing how complex catchment dynamics can be reconstructed solely from rainfall and runoff measurements. We also show how the approach discovers surrogate models that can replicate the dynamics of a much more complex process-based model, but at a fraction of computational complexity. We discuss how the resulting parsimonious representation of watershed dynamics provides theoretical insight and computational efficiency to enable automated predictions across large areas.