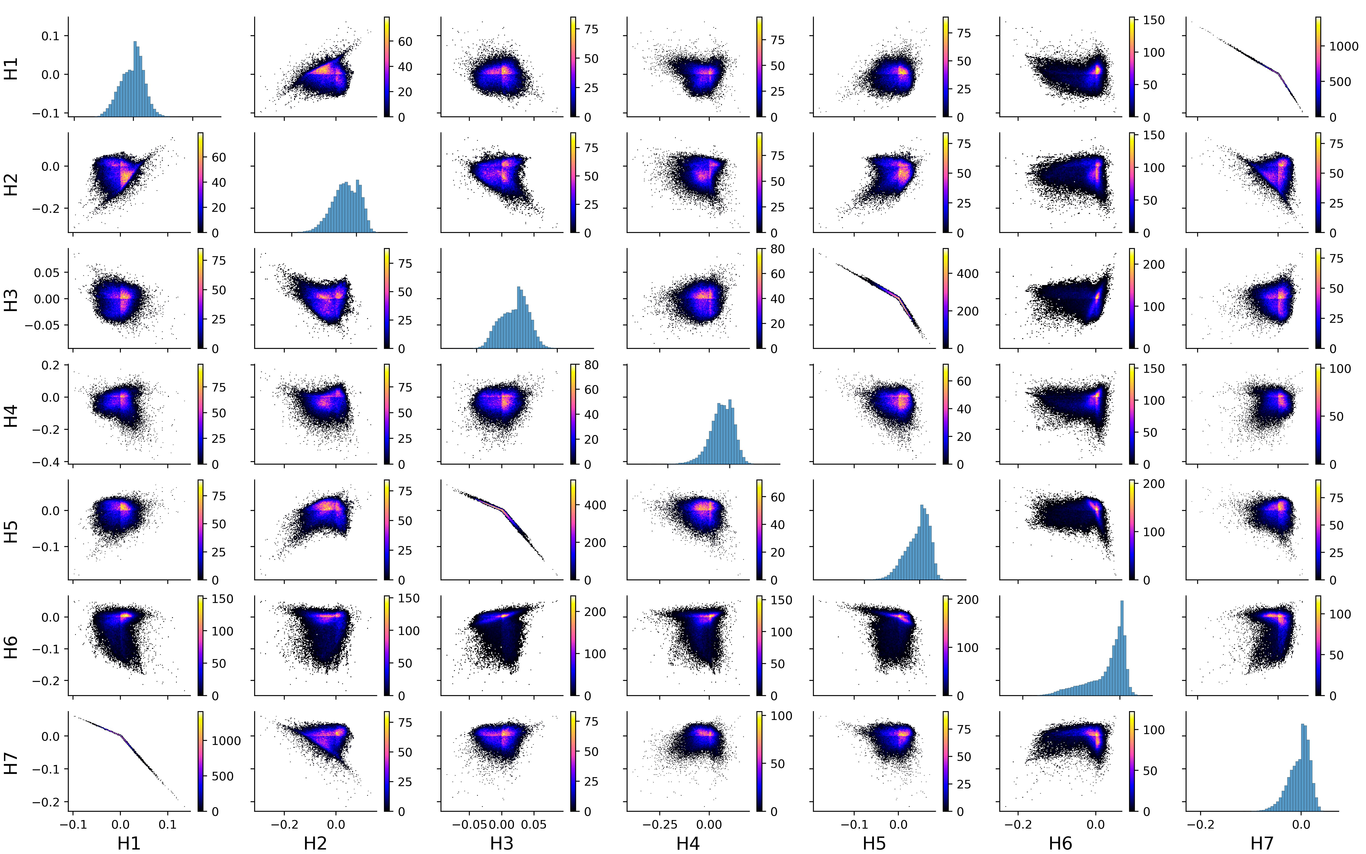
We devised a new data analysis technique to identify the threat level of solar active regions by processing a combined data set of magnetic field properties and flaring activity. The data set is composed of two elements: a reduced factorization of SHARP properties of the active regions, and information about the flaring activity at the time of measurement of the SHARP parameters. Machine learning is used to reduce the data and to subsequently classify the active regions. For this classification we used both supervised and unsupervised clustering. The following processing steps are applied to reduce and enhance the SHARP data: outlier detection, redundancy elimination with common factor analysis, addition of sparsity with autoencoders, and construction of a balanced data set with under- and over-sampling. Supervised clustering (based on K-nearest neighbors) produces very good results on the strong X- and M-flares, with TSS scores of respectively 93% and 75%. Unsupervised clustering (based on K-means and Gaussian Mixture Models) shows that non-flaring and flaring active regions can be distinguished, but there is not enough information in the data set for the technique to identify clear differences between the different flaring levels. This work shows that the SHARP database lacks information to accurately make flaring predictions: there is no clear hyperplane in the SHARP parameter space, even after a detailed cleaning procedure, that can separate active regions with different flaring activity. We propose instead, for future projects, to complement the magnetic field parameters with additional information, like images of the active regions.