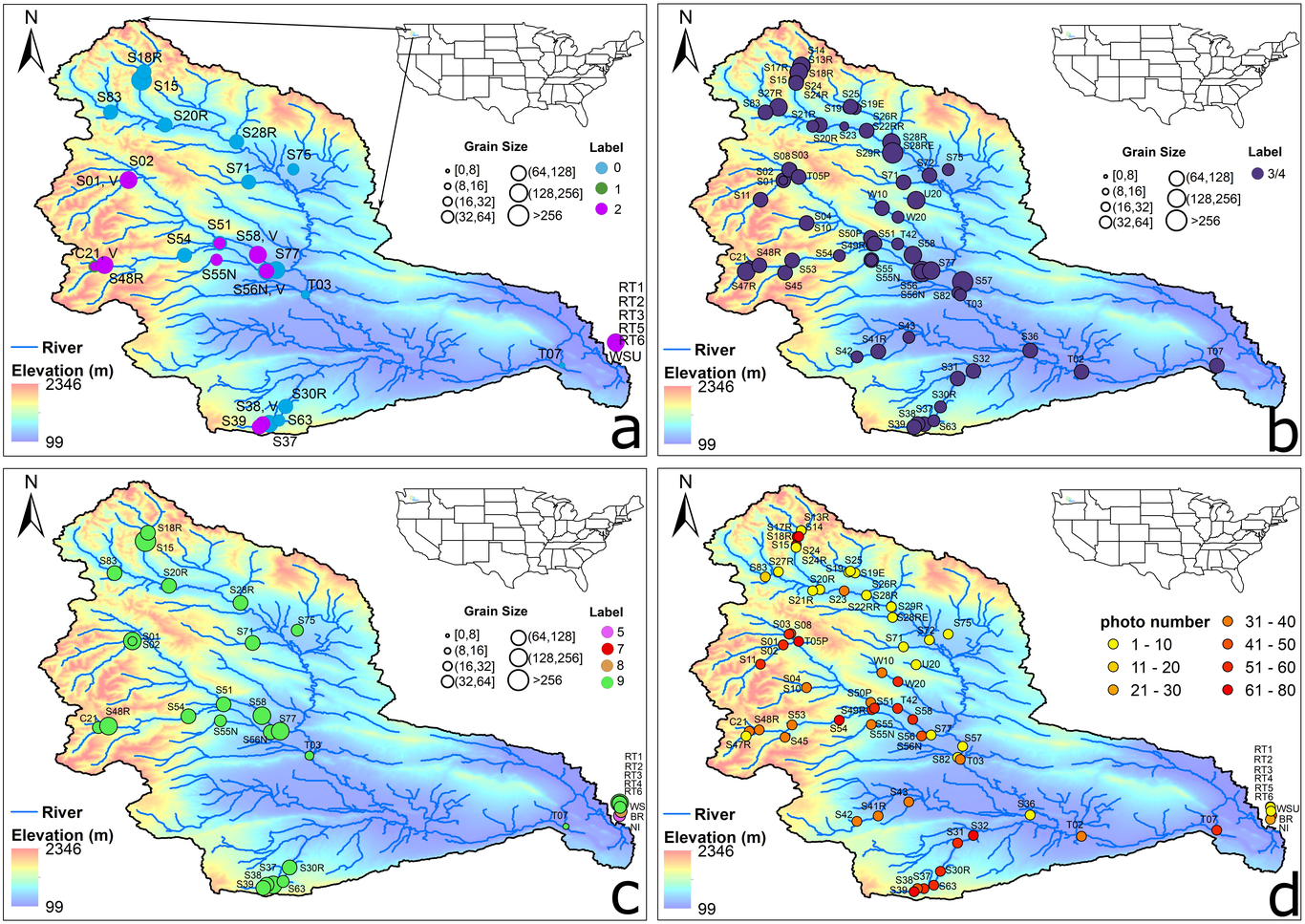
Streambed grain sizes and hydro-biogeochemistry (HBGC) control river functions. However, measuring their quantities, distributions, and uncertainties is challenging due to the diversity and heterogeneity of natural streams. This work presents a photo-driven, artificial intelligence (AI)-enabled, and theory-based workflow for extracting the quantities, distributions, and uncertainties of streambed grain sizes and HBGC parameters from photos. Specifically, we first trained You Only Look Once (YOLO), an object detection AI, using 11,977 grain labels from 36 photos collected from 9 different stream environments. We demonstrated its accuracy with a coefficient of determination of 0.98, a Nash–Sutcliffe efficiency of 0.98, and a mean absolute relative error of 6.65% in predicting the median grain size of 20 testing photos. The AI is then used to extract the grain size distributions and determine their characteristic grain sizes, including the 5th, 50th, and 84th percentiles, for 1,999 photos taken at 66 sites. With these percentiles, the quantities, distributions, and uncertainties of HBGC parameters are further derived using existing empirical formulas and our new uncertainty equations. From the data, the median grain size and HBGC parameters, including Manning’s coefficient, Darcy-Weisbach friction factor, interstitial velocity magnitude, and nitrate uptake velocity, are found to follow log-normal, normal, positively skewed, near log-normal, and negatively skewed distributions, respectively. Their most likely values are 6.63 cm, 0.0339 s·m-1/3, 0.18, 0.07 m/day, and 1.2 m/day, respectively. While their average uncertainty is 7.33%, 1.85%, 15.65%, 24.06%, and 13.88%, respectively. Major uncertainty sources in grain sizes and their subsequent impact on HBGC are further studied.