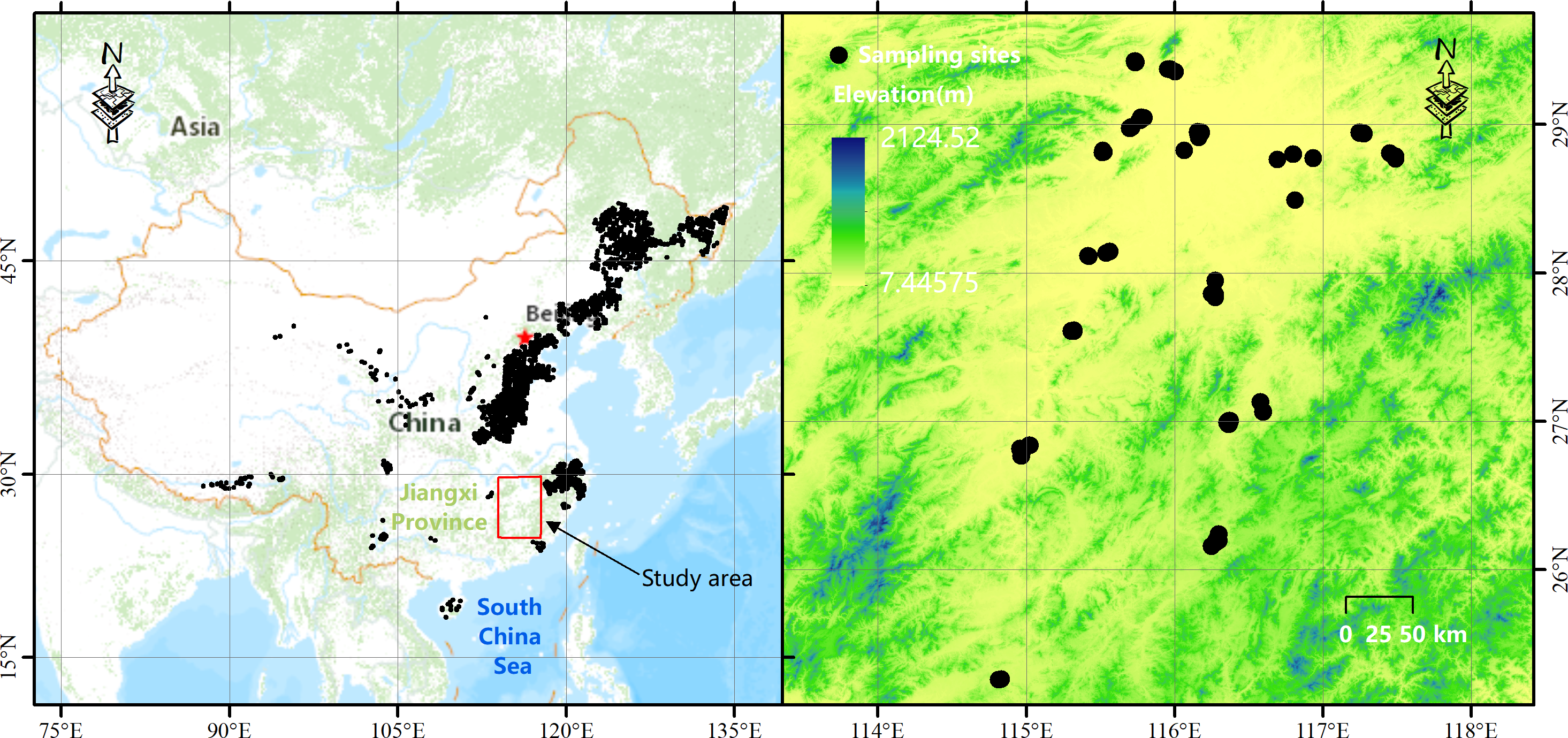
The aim of this paper was to compare the prediction performance of three strategies: general global Partial least squares regression (PLSR) using CSSL with and without spiking samples, memory-based learning (MBL) using CSSL with and without spiking samples and general PLSR using only spiking samples to predict soil organic matter in the target area. When using spiked subsets, we also investigated the prediction performance of the extra-weighted subsets. A series of spiking subsets randomly selected from the total spiking samples were selected by conditioned Latin hypercube sampling (cLHS) from the target sites. We calculated the mean squared Euclidean distance (msd) of different spiking subsets with the distribution density function of their vis–NIR spectra only and statistically inferred the optimal sampling set size to be 30. Our study showed that when the number of spiking were lower than 30, the predicted accuracy derived from global PLSR using CSSL spiked with and without extra-weighted samples was greater than the predicted accuracy derived from the general PLSR using the corresponding number of spiking samples only (RMSE 5.57–5.98 v.s. RMSE 6.76). Global PLSR using CSSL spiked with the statistically optimal local samples can achieve higher predicted performance (with a mean RMSE of 5.75). MBL spiked with five extra-weighted optimal spiking samples achieved the best accuracy with an RMSE of 3.98, an R2 of 0.70, a bias of 0.04 and an LCCC of 0.81. The msd is a simple and effective method to determine an adequate spiking size using only vis–NIR data.