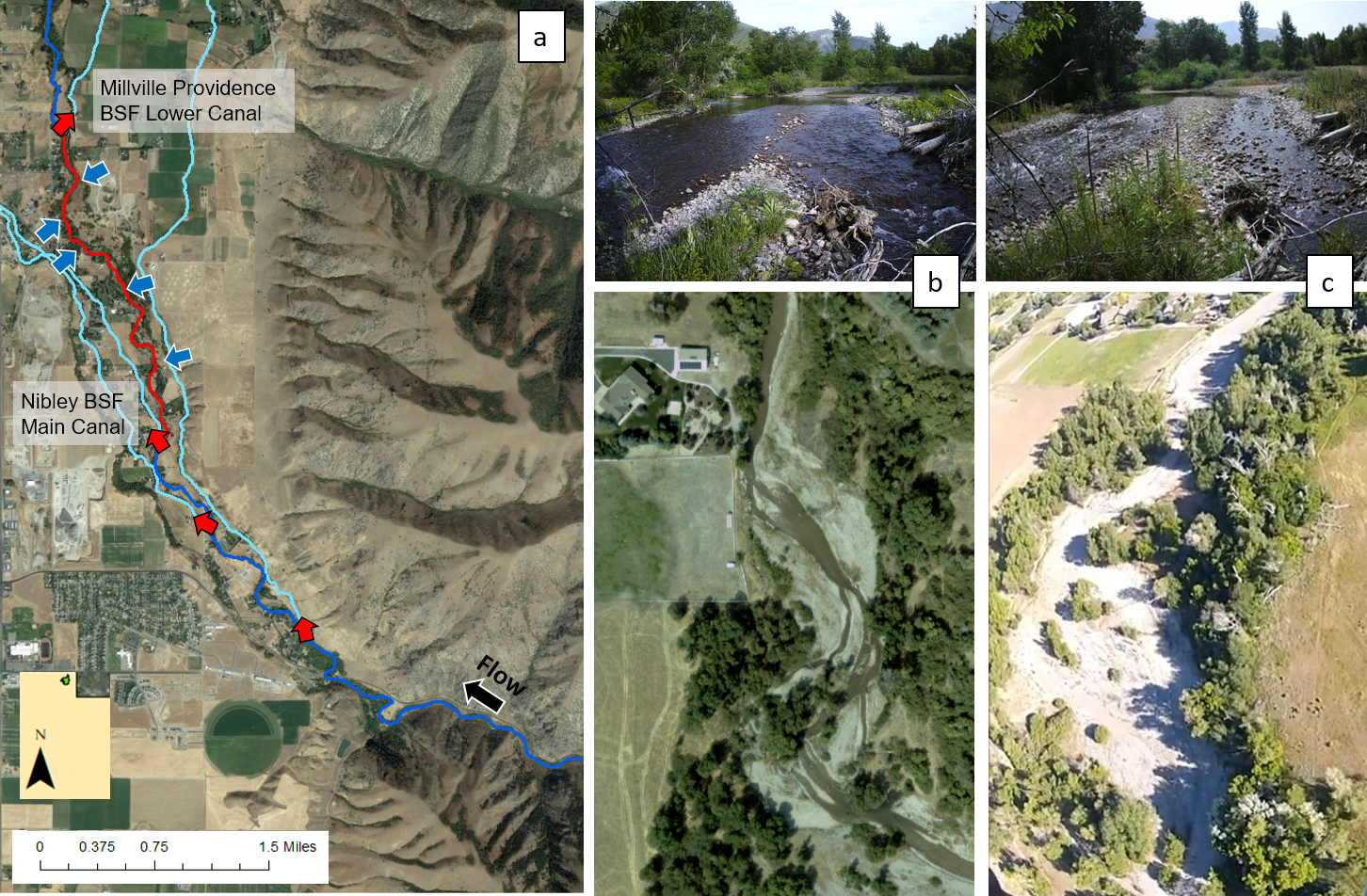
Reach-scale morphological channel classifications are underpinned by the theory that each channel type is related to an assemblage of reach- and catchment-scale hydrologic, topographic, and sediment supply drivers. However, the relative importance of each driver on reach morphology is unclear, as is the possibility that different driver assemblages yield the same reach morphology. Reach-scale classifications have never needed to be predicated on hydrology, yet hydrology controls discharge and thus sediment transport capacity. The scientific question is: do two or more regions with quantifiable differences in hydrologic setting end up with different reach-scale channel types, or do channel types transcend hydrologic setting because hydrologic setting is not a dominant control at the reach scale? This study answered this question by isolating hydrologic metrics as potential dominant controls of channel type. Three steps were applied in a large test basin with diverse hydrologic settings (Sacramento River, California) to: (1) create a reach-scale channel classification based on local site surveys, (2) categorize sites by flood magnitude, dimensionless flood magnitude, and annual hydrologic regime type, and (3) statistically analyze two hydrogeomorphic linkages. Statistical tests assessed the spatial distribution of channel types and the dependence of channel type morphological attributes by hydrologic setting. Results yielded ten channel types. Nearly all types existed across all hydrologic settings, which is perhaps a surprising development for hydrogeomorphology. Downstream hydraulic geometry relationships were statistically significant. In addition, cobble-dominated uniform streams showed a consistent inverse relationship between slope and dimensionless flood magnitude, an indication of dynamic equilibrium between transport capacity and sediment supply. However, most morphological attributes showed no sorting by hydrologic setting. This study suggests that median hydraulic geometry relations persist across basins and within channel types, but hydrologic influence on geomorphic variability is likely due to local influences rather than catchment-scale drivers.