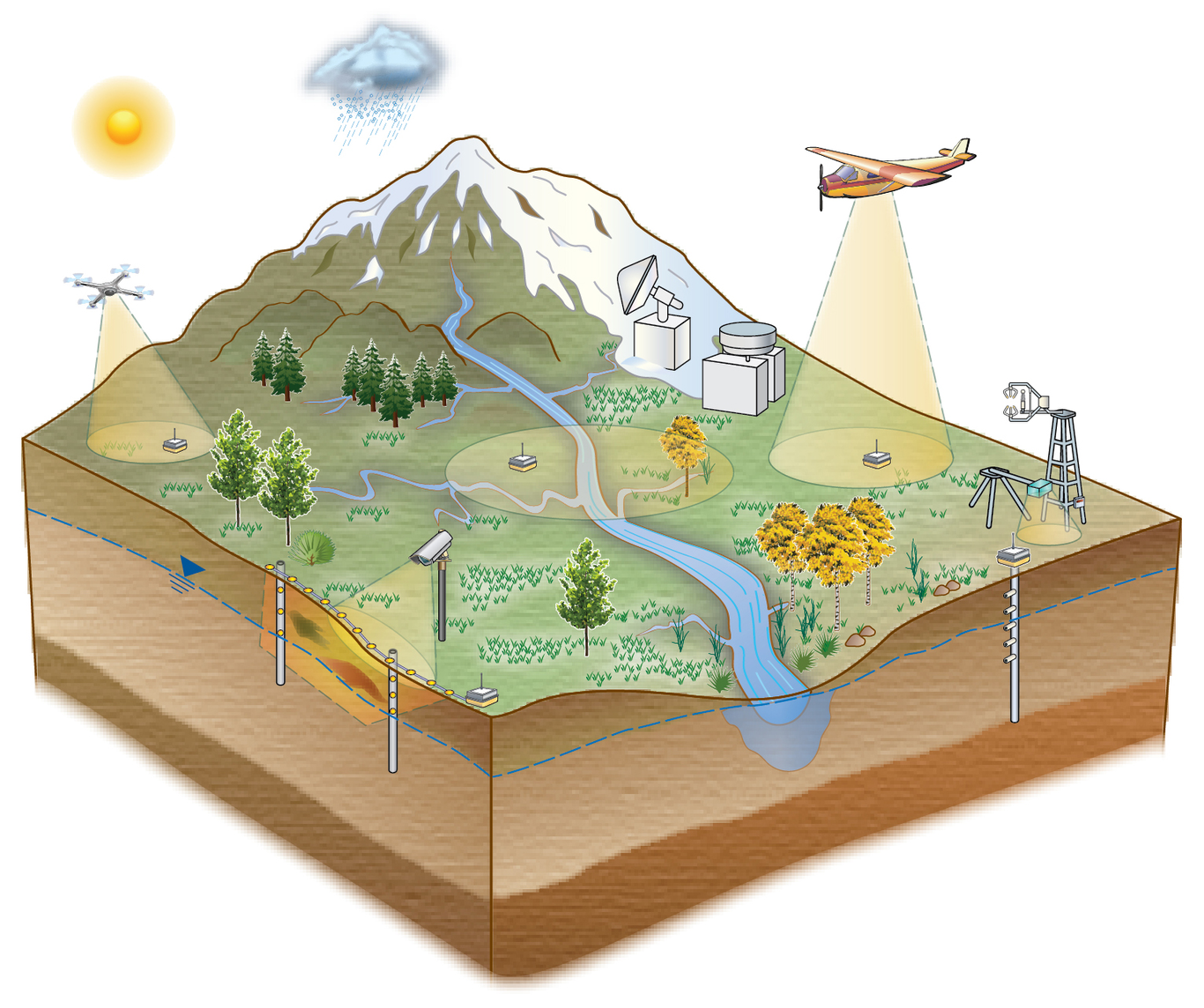
The Colorado East River Community Observatory Data Collection Zarine Kakalia1,2, Charuleka Varadharajan1,†, Erek Alper3, Eoin L. Brodie1, Madison Burrus1, Rosemary W.H. Carroll4, Danielle Christianson5, Wenming Dong1,Valerie Hendrix4, Matthew Henderson4, Susan Hubbard1, Douglas Johnson2, Roelof Versteeg2, Kenneth H. Williams1, and Deborah A. Agarwal41Lawrence Berkeley National Laboratory, Earth and Environmental Sciences Area, Berkeley, CA 94720 USA2 University of California Berkeley, College of Natural Resources, Berkeley, CA 94720 USA3Subsurface Insights, LLC, Hanover, NH 03755 USA4Desert Research Institute, Reno, NV 89512 USA5Lawrence Berkeley National Laboratory, Computing Sciences Area, Berkeley, CA 94720 USA†Corresponding Author:Charuleka Varadharajan ([email protected]).1 Cyclotron Road, 84-142 (M/S 74R316C), Berkeley, California, 94720Ph: 510-495-8890