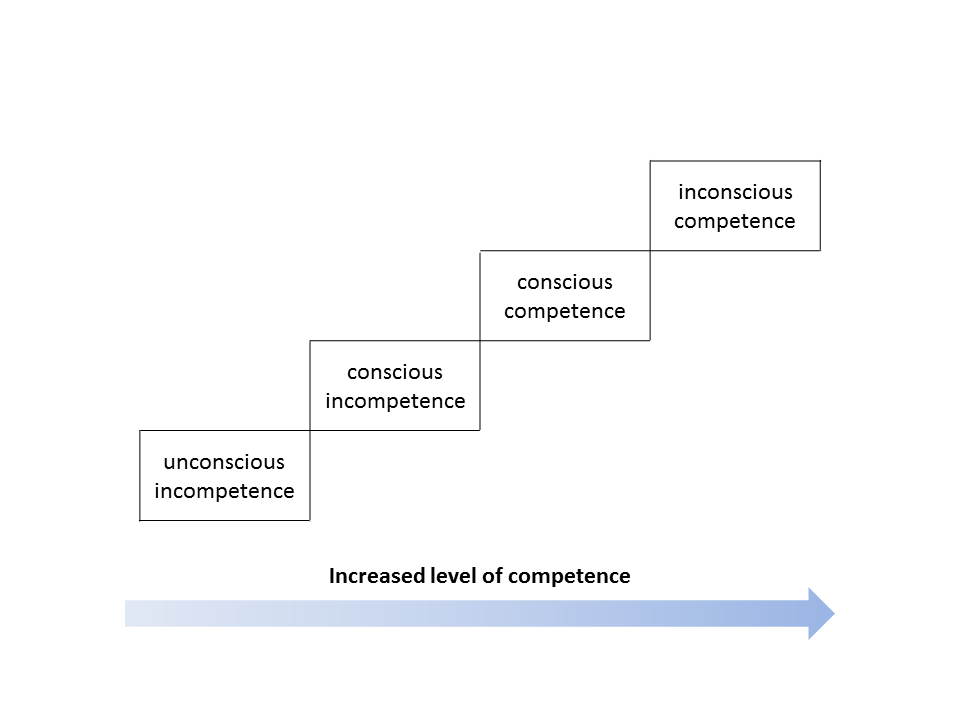
ScopeThis document consist of a textual sketch aiming for each question of the SNSF-DMP to introduce technical elements for the answer:in the form of one or two generic sentences that researches can customize,or in the form of several generic elements that can be selected by researchers depending on their projects.Responsiblity: Aude.Swiss National Science Foundation Data Management Plan: DMP Canevas for the mySNF formThis canevas has been based on the SNF guidelines http://www.snf.ch/SiteCollectionDocuments/DMP_content_mySNF-form_en.pdf and several concrete examples of DMPs including more specifically the ones available on the DCC and UNIGE websites: http://www.dcc.ac.uk/resources/data-management-plans/guidance-exampleshttps://www.unige.ch/researchdata/en/make-plan/all/dmp-fns/http://www.gla.ac.uk/media/media_418166_en.pdhttp://www.gla.ac.uk/media/media_441723_en.pdf1. Data collection and documentation1.1 What data will you collect, observe, generate or re-use?Questions you might want to consider:- What type, format and volume of data will you collect, observe, generate or reuse?- Which existing data (yours or third-party) will you reuse?Briefly describe the data you will collect, observe or generate. Also mention any existing data that will be (re)used. The descriptions should include the type, format and content of each dataset. Furthermore, provide an estimation of the volume of the generated datasets.(This relates to the FAIR Data Principles F2, I3, R1 & R1.2)Examples of answerThe data produced from this research project will fall into two categories:1. The various reaction parameters required for optimisation of the chemical transformation.2. The spectroscopic and general characterisation data of all compounds produced during the work.We anticipate that the data produced in category 1 will amount to approximately 10 MB and the data produced in category 2 will be in the range of 4 - 5 GB.***This project will work with and generate three main types of raw data.1. Images from transmitted-light microscopy of giemsa-stained squashed larval brains.2. Images from confocal microscopy of immunostained whole-mounted larval brains.3. Western blot data.All data will be stored in digital form, either in the format in which it was originally generated (i.e. Metamorph files, for confocal images; Spectrum Mill files, for mass spectra with results of mass spectra analyses stored in Excel files; tiff file s for gel images; Filemaker Pro files for genetics records), or will be converted into a digital form via scanning to create tiff or jpeg files (e.g. western blots or other types of results).Measurements and quantification of the images will be recorded in spreadsheets. Micrograph data is expected to total between 100GB and 1TB over the course of the project. Scanned images of western blots are expected to total around 1GB over the course of the project. Other derived data (measurements and quantifications) are not expected to exceed 10MB.1.2 How will the data be collected, observed or generated?Questions you might want to consider:- What standards, methodologies or quality assurance processes will you use?- How will you organize your files and handle versioning?Explain how the data will be collected, observed or generated. Describe how you plan to control and document the consistency and quality of the collected data: calibrationprocesses, repeated measurements, data recording standards, usage of controlled vocabularies, data entry validation, data peer review, etc.Discuss how the data management will be handled during the project, mentioning for example naming conventions, version control and folder structures. (This relates to the FAIR Data Principle R1)Examples of answerThe reaction conditions will be recorded and collated using Excel spreadsheets and named according to each generation of reaction.The various experimental procedures and associated compound characterisation will be written up using the Royal Society of Chemistry standard formatting in a Word document. The associated NMR spectra will be collated in chronological order in a.pdf document.These are standard practices for synthetic methodology projects.***All samples on which data are collected will be prepared according to published standard protocols in the field. Files will be named according to a pre-agreed convention. The dataset will be accompanied by a README file which will describe the directory hierarchy and file naming convention.Each directory will contain an INFO.txt file describing the experimental protocol used in that experiment. It will also record any deviations from the protocol and other useful contextual information.Microscope images capture and store a range of metadata (field size, magnification, lens phase, zoom, gain, pinhole diameter etc.) with each image.This should allow the data to be understood by other members of our research group and add contextual value to the dataset should it be reused in the future.1.3 What documentation and metadata will you provide with the data?Questions you might want to consider:- What information is required for users (computer or human) to read and interpret the data in the future?- How will yougenerate this documentation?- What community standards (if any) will be used to annotate the (meta)data?Describe all types of documentation (README files, metadata, etc.) you will provide to help secondary users to understand and reuse your data. Metadata should at least include basic details allowing other users (computer or human) to find the data. This includes at least a name and a persistent identifier for each file, the name of the person who collected or contributed to the data, the date of collection and the conditions to access the data.Furthermore, the documentation may include details on the methodology used, information about the performed processing and analytical steps, variable definitions, references to vocabularies used, as well as units of measurement.Wherever possible, the documentation should follow existing community standards and guidelines. Explain how you will prepare and share this information. (This relates to the FAIR Data Principles I1, I2, I3, R1, R1.2 & R1.3)Examples of answerThe data will be accompanied by the following contextual documentation, according to standard practice for synthetic methodology projects:1. Spreadsheet documents which detail the reaction conditions.2. Text files which detail the experimental procedures and compound characterisation.Files and folders will be named according to a pre-agreed convention. The final dataset as deposited in the institutional data repository will also be accompanied by a README file listing the contents of the other files and outlining the file-naming convention used.***Metadata will be tagged in XML using the Data Documentation Initiative (DDI) format. The codebook will contain information on study design, sampling methodology, fieldwork, variable-level detail, and all information necessary for a secondary analyst to use the data accurately and effectively.It will be the responsibility of each researcher to annotate their data with metadata, and it will be the responsibility of the Principal Investigator to check weekly (during the field season, monthly otherwise) with all participants to assure data is being properly processed, documented, and stored.All the datasets produced by the project will be published under a GNU licence.2. Ethics, legal and security issues2.1 How will ethical issues be addressed and handled?Questions you might want to consider:- What is the relevant protection standard for your data? Are you bound by a confidentiality agreement?- Do you have the necessary permission to obtain, process, preserve and share the data? Have the people whose data you are using been informed or did they give their consent?- What methods will you use to ensure the protection of personal or other sensitive data?Ethical issues in research projects demand for an adaptation of research data management practices, e.g. how data is stored, who can access/reuse the data and how long the data is stored. Methods to manage ethical concerns may include: anonymization of data; gain approval by ethics committees; formal consent agreements. You should outline that all ethical issues in your project have been identified, including the corresponding measures in data management. (This relates to the FAIR Data Principle A1)Examples of answerThere are no ethical issues in the generation of results from a synthetic methodology project. There are no human subject or samples involved***This project will generate data designed to study the prevalence and correlates of DSM III-R psychiatric disorders and patterns and correlates of service utilization for these disorders in a nationally representative sample of over 8000 respondents. The sensitive nature of these data will require that the data be released through a restricted use contract.2.2 How will data access and security be managed?Questions you might want to consider:- What are the main concerns regarding data security, what are the levels of risk and what measures are in place to handle security risks?- How will you regulate data access rights/permissions to ensure the security of the data?- How will personal or other sensitive data be handled to ensure safe data storage and transfer?If you work with personal or other sensitive data you should outline the security measures in order to protect the data. Please list formal standards which will be adopted in your study. An example is ISO 27001-Information security management. Furthermore, describe the main processes or facilities for storage and processing of personal or other sensitive data. (This relates to the FAIR Data Principle A1)Examples of answerThe data will be processed and managed in a secure non-networked environment using virtual desktop technology.***All interviewees and focus group participants will sign a Consent form agreed to by the School ethics committee. We have guaranteed anonymity to our interviewees and focus group participants. Therefore we will not be depositing .wav files as this would compromise that guarantee. However, anonymised transcripts of the interviews and focus groups will be deposited. We will make sure consent forms make provision for future sharing of data. All identifying information will be kept in a locked filing cabinet and not stored with electronic files.2.3 How will you handle copyright and Intellectual Property Rights issues?Questions you might want to consider:- Who will be the owner of the data?- Which licenses will be applied to the data?- What restrictions apply to the reuse of third-party data?Outline the owners of the copyright and Intellectual Property Right (IPR) of all data that will be collected and generated including the licence(s). For consortia, an IPR ownership agreement might be necessary. You should comply with relevant funder, institutional, departmental or group policies on copyright or IPR. Furthermore, clarify what permissions are required should third-party data be re-used. (This relates to the FAIR Data Principles I3 & R1.1)Examples of answerThe research is not expected to lead to patents. IPR issues will be dealt with in line with University of Glasgow policy and necessary guidance will be sought from the IPR and Commercialisation Team.***This project is being carried out in collaboration with an industrial partner. The intellectual property rights are set out in the collaboration agreement. The intellectual property generated from this project will be fully exploited with help from the University of Glasgow's IP and Commercialisation Office. The aim is to patent the final procedure and then publish the work in a research journal.3. Data storage and preservation3.1 How will your data be stored and backed-up during the research?Questions you might want to consider:- What are your storage capacity and where will the data be stored?- What are the back-up procedures?Please mention what the needs are in terms of data storage and where the data will be stored.Please consider that data storage on laptops or hard drives, for example, is risky. Storage through IT teams is safer. If external services are asked for, it is important that this does not conflict with the policy of each entity involved in the project, especially concerning the issue of sensitive data.Please specify your back-up procedure (frequency of updates, responsibilities, automatic/manual process, security measures, etc.)Examples of answerStorage and back up will be in three places:● On Laptop of [Name of Researcher]● On a portable storage device (hard drive)● On the University of Glasgow server.[Name of Researcher] will be responsible for the storage and back up of data. This will be done weekly.Both the laptop and external storage devise will be password protected. The risks are that the computer will be hacked and the external drive stolen. The laptop has anti-virus software installed which is updated daily. The external devise is in a locked cabinet. Moreover the data files will also be password protected. The paper consent forms from interviewees/focus group participants will be kept in a locked cabinet in the university office of [Name of Researcher].***Original notebooks and hardcopies of all NMR and mass spectra are stored in the PI’s laboratory. Additional electronic data will be stored on the PI’s computer, which is backed up daily. Additionally, the laboratory will make use of the PI’s lab server space at Tufts for a second repository of data storage. The PI’s lab has access to up to 1 terabyte of information storage at Tufts, which can be expanded if needed.All the project data will be stored using Tufts University Information Technology resources. The storage is backed up to LTO-4 tape on a daily and weekly basis and stored offsite at Iron Mountain facilities.3.2 What is your data preservation plan?Questions you might want to consider:- What procedures would be used to select data to be preserved?- What file formats will be used for preservation?Please specify which data will be retained, shared and archived after the completion of the project and the corresponding data selection procedure (e.g. long-term value, potential value for re-use, obligations to destroy some data, etc.). Please outline a long-term preservation plan for the datasets beyond the lifetime of the project.In particular, comment on the choice of file formats and the use of community standards.Examples of answerData will be stored for a minimum of three years beyond award period, per NSF guidelines. If inventions or new technologies are made in connection data, access to data will be restricted until invention disclosures and/or provisional patent filings are made with the EPFL Technical Transfer Office (TTO).***We will preserve the data for 10 years on university servers and also deposit the data in a UK data archive. We will deposit our data at the end of the project in an appropriate data depository e.g. UK Data Archive and/or the Consortium of European Social Science Data Archives. There is no additional cost. Where possible we will store files in open archival formats e.g. word files converted to .txt files and excel files converted to .csv. Where this is not possible we will include information on software used and version number.4. Data sharing and reuse4.1 How and where will the data be shared?Questions you might want to consider- On which repository do you plan to share your data?- How will potential users find out about your data?Consider how and on which repository the data will be made available. The methods applied to data sharing will depend on several factors such as the type, size, complexity and sensitivity of data.Please also consider how the reuse of your data will be valued and acknowledged by other researchers.(This relates to the FAIR Data Principles F1, F3, F4, A1, A1.1, A1.2 & A2)Examples of answerSome of the ongoing data will be shared on [Researcher1]’s Github page (results and code from NetLogo, data from twitter searches).For all other data we will use the University of Glasgow Institutional Data Repository, 'Enlighten: Research Data', where we can direct interested parties, rather than handling each request individually.***Datasets from this work which underpin a publication will be deposited in Enlighten: Research Data, the University of Glasgow’s institutional data repository, and made public at the time of publication. Data in the repository will be stored in accordance with funder and University data policies. Files deposited in Enlighten: Research Data will be given a Digital Object Identifier (DOI) and the associated metadata will be listed in the University of Glasgow Research Data Registry and the DataCite metadata store. The retention schedule for data in Enlighten: Research Data will be 10 years from date of deposition in the first instance, with extensions applied to datasets which are subsequently accessed. This complies with both University of Glasgow guidance and funder policies.Enlighten: Research Data is backed by commercial digital storage wich is audited on a twice yearly basis for compliance with the ISO27001 Information Security Management standard.The DOI issued to datasets in the repository can be included as part of a data citation in publications, allowing the datasets underpinning a publication to be identified and accessed.Metadata about datasets held in the University Registry will be publicly searchable and discoverable and will indicate how and on what terms the dataset can be accessed.4.2 Are there any necessary limitations to protect sensitive data?Questions you might want to consider:- Under which conditions will the data be made available (timing of data release, reason for delay if applicable)?Data have to be shared as soon as possible, but at the latest at the time of publication of the respective scientific output.Restrictions may be only due to legal, ethical, copyright, confidentiality or other clauses.Consider whether a non-disclosure agreement would give sufficient protection for confidential data.(This relates to the FAIR Data Principles A1 & R1.1)Examples of answerData which underpins any publication will be made available at the time of publication.All unpublished data will be deposited in a data repository 12 months after the end of the award.***Astronomical data will be diffused but under an embargo of one year for priority of exploitation reasons.***Personal data will be anonymized before diffusion based on the recommendations from the Commission nationale de l'informatique et des libertés (CNIL).***Data will be made available under Creative Commons License CC-BY.For more licensing options, please feel free to explore this website: https://creativecommons.org/share-your-work/